Au détour d’une conversation avec des collègues, l’idée nous est venue de combiner nos apprentissages dans le domaine du big data et notre curiosité sur un sujet dans l’air du temps : « Qu’y a-t-il exactement dans notre assiette ? ».
Voici quelques réponses issues d’un travail réalisé en équipe il y a quelques temps et qui nous a permis de mettre en pratique un cas simple avec des données à forte volumétrie.
Open Food Facts

“Open Food Facts” est un projet collaboratif gérant une base de données libre et ouverte sur les produits alimentaires commercialisés. Pour chaque produit, on retrouve de nombreuses informations, notamment ses ingrédients et sa composition nutritionnelle ainsi que les données concernant sa mise en vente : origines, quantité, marques, emballages, enseignes de vente… A partir de ces informations renseignées par des utilisateurs, des évaluations et des scores sont calculés pour classer le produit (Nutri-score, classement NOVA, éco-score).
L’objectif est que le consommateur puisse avoir un regard éclairé sur la qualité des produits qu’il choisit et leur empreinte carbone, pour éventuellement changer ses habitudes alimentaires.
La base de données “Open Food Facts” contient plus 2.8 millions de produits à ce jour dans de nombreux pays et reste en constante évolution.
Voici un exemple de fiche produit avec une partie des informations qu’on y trouve :

Chaque produit dispose de données potentiellement exploitables comme : son nom générique, ses valeurs nutritionnelles, son conditionnement (emballage plastique, verre, carton…), la marque, les magasins de vente, pays de vente, etc. et enfin les scores ou classements suivants :

Pour chaque produit, des données peuvent être manquantes, non mises à jour voire erronées. La base de données est en effet en constante évolution et qui plus est, mise à jour par des acteurs variés, ce qui ne simplifie pas le traitement de la base.
Environnement de traitement des données
Nous avons importé un extrait de la base de données “Open Food Facts” sous format texte csv ; elle contient 600 000 lignes ou produits et 180 colonnes ou caractéristiques ce qui en fait un jeu de données modeste pour un cas d’étude « big data ».
Pour jouer avec ce « petit » jeu de big data, nous mettons en place un environnement Hadoop complet sur un cluster de machines EURODECISION. Nous allons utiliser quelques outils de l’écosystème Hadoop :
- HDFS pour le stockage distribué des données sur un cluster ;
- YARN pour gérer les ressources distribuées ;
- Spark pour le traitement des données : filtres, agrégations, classements.
Traitement des données
Les données doivent être filtrées et nettoyées pour qu’elles puissent être utilisées. La base de données étant renseignée par des utilisateurs aux profils variés, les valeurs saisies sont hétérogènes et peuvent être erronées. Il n’existe pas de référentiel commun (exemple : liste de magasins) aussi une même donnée peut être renseignée de façon différente (MagasinU = Magasin U). Des algorithmes de vérification des données sont appliqués sur la base Open Food Facts mais cela n’est pas suffisant pour avoir une base complètement propre.
Dans notre étude,
- On ne s’intéresse qu’aux produits disponibles en France ;
- Pour chacune des caractéristiques qu’on étudiera plus tard, on s’assure qu’une valeur est renseignée. Ex : ‘NULL’ n’est pas un nutri-score valide ;
- On explose (met à plat) les données, par exemple un produit disponible dans plusieurs enseignes différentes aura sa ligne dupliquée ;
- On standardise les noms des enseignes (accents, espaces, orthographe…). Voici un exemple avec l’enseigne Mark & Spencer et les différentes versions que l’on retrouve de son orthographe en base :

- Enfin, on retire les produits présents dans des enseignes avec peu de références et peu de magasins en France.
Globalement, après ce nettoyage et filtrage grossier il ne reste qu’à peine plus de 25 % de données exploitables. C’est peu, mais suffisant pour réaliser notre étude.
Alors finalement, quelles sont les enseignes où l’on peut trouver des produits sains ? On se propose de regarder pour cela le classement des produits en termes de nutri-scores mais également la classification NOVA.
Nutri-score
Le nutri-score est un système d’étiquetage nutritionnel à 5 niveaux allant de A (vert) à E (rouge) et a pour but de faciliter la compréhension des informations nutritionnelles pour favoriser le choix de produits plus sains (moins gras, moins salés, moins sucrés). Il est apposé sur les produits sur la base du volontariat par les producteurs.
Plus d’infos : site web Santé Publique France

Attention, certains produits n’entrent pas dans l’obligation de déclaration nutritionnelle et n’auront donc pas d’étiquetage Nutri-Score. C’est le cas notamment des produits non transformés qui comprennent qu’un seul ingrédient ou une seule catégorie d’ingrédients (fruits ou légumes frais, viandes crues découpées, miel…) et des eaux.
Le nutri-score est calculé par un système de points avec bonus et malus. Côté malus, on retrouve l’apport calorique, les teneurs en sucre, graisse saturée et sel. Et côté bonus, un aliment avec de forte teneur en fruit, légume, protéine et fibre sera privilégié.
Quelques repères :

Classement nutri-score par enseigne
En reprenant dans nos données le nutri-score renseigné (ou calculé), la liste des produits et les enseignes les commercialisant on arrive assez simplement à classer les enseignes françaises.
Par exemple, on voit des différences, légères, parmi les 10 enseignes les plus représentées, en nombre de produits. Le pourcentage de produits avec nutri-score A ou B ne dépassant pas 38 % dans ce cas.
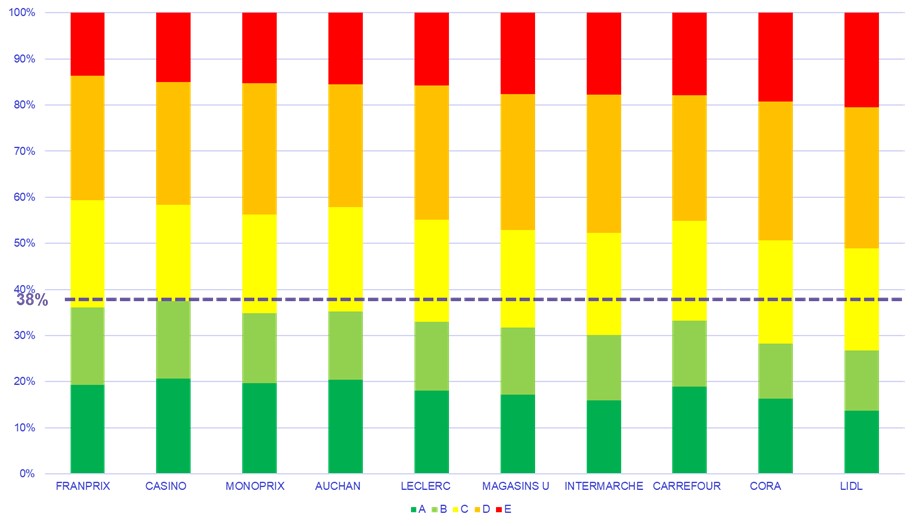
Figure 1 – Répartition des produits par nutri-score, par enseigne.
Si l’on se concentre à présent sur les 10 enseignes ayant la plus grande part de produits classés A ou B, on trouve des parts de produits « sains » comprise entre 35 % et 49 %.
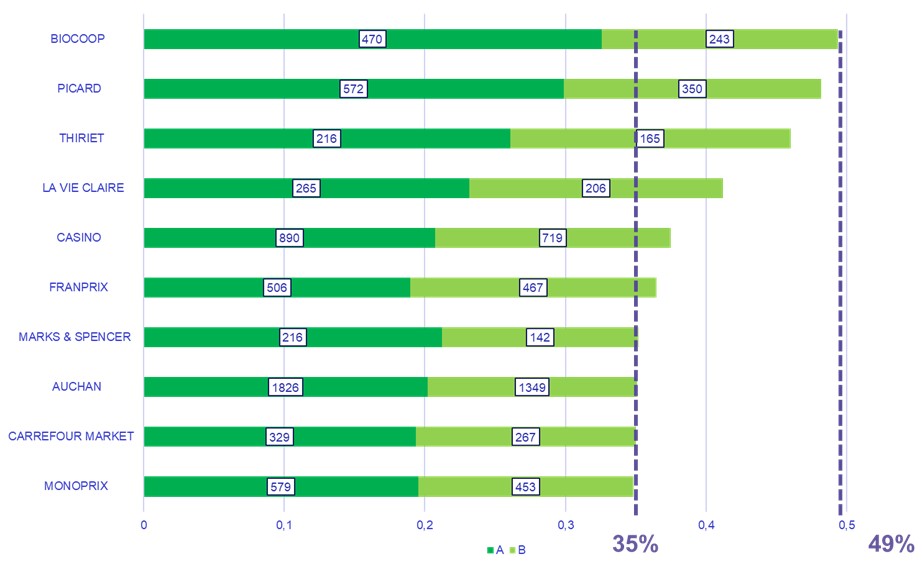
Figure 2 – Part des produits des classes A et B (les plus « sains ») pour les 10 enseignes les plus vertueuses.
Les enseignes proposant la plus grande part de produits avec de bons nutri-scores sont celles qui commercialisent le plus de fruits et légumes frais ou surgelés (Biocoop, La vie Claire, Pïcard, Thiriet) et peu transformés. Nous remarquons également la disparité entre les enseignes dans le nombre de références dans chaque catégorie.
Inversement les 10 enseignes qui ont la plus grande part de produits classés D ou E sont les suivantes :
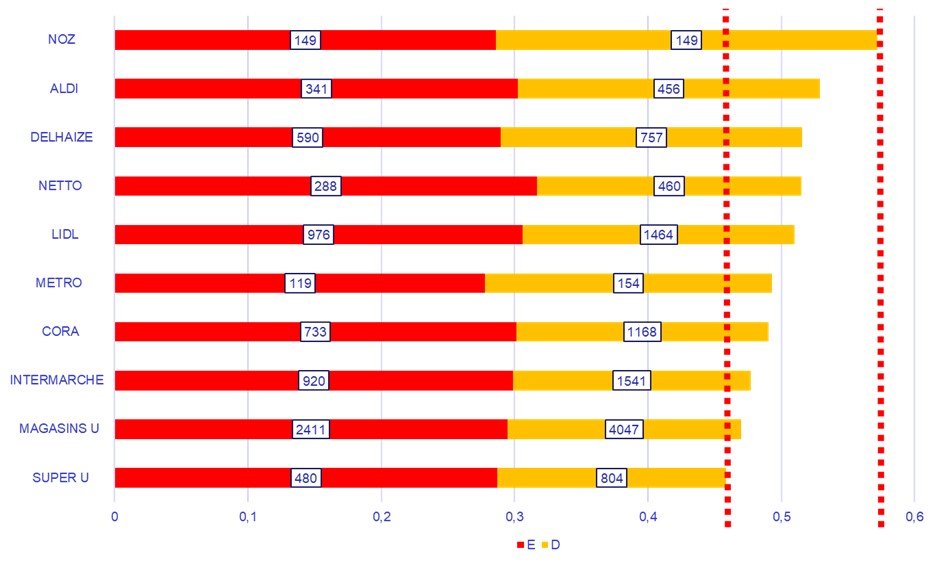
Figure 3 – Part des produits des classes D et E (les moins « sains ») pour les 10 enseignes les moins vertueuses.
Pour ces enseignes, la part de produits dont le score est D ou E est proche de 50 %. En queue de peloton nous retrouvons des enseignes discount ou hard-discount.
Classification NOVA
La classification NOVA est une répartition des aliments en quatre groupes de 1 (vert) à 4 (rouge) en fonction du degré de transformation des matières dont ils sont constitués :

- NOVA 1 : Aliments peu ou non transformés (viande, poisson, œufs, fruits, légumes…) ;
- NOVA 2 : Ingrédients culinaires (huile, sucre, sel…) ;
- NOVA 3 : Aliments transformés (conserves, fromage, pain…) ;
- NOVA 4 : Aliments ultratransformés (pâte à tartiner, bonbon, yaourt, soda…).
Cette classification a pour objectif de sensibiliser le consommateur aux transformations apportées aux produits qu’il trouve en magasin.
Classification NOVA par enseigne
Comme pour le nutri-score, on peut faire l’exercice sur la classification NOVA pour les enseignes françaises.
Par exemple intéressons-nous aux 10 enseignes les plus représentées et à leur part de produits dans chaque classe NOVA.
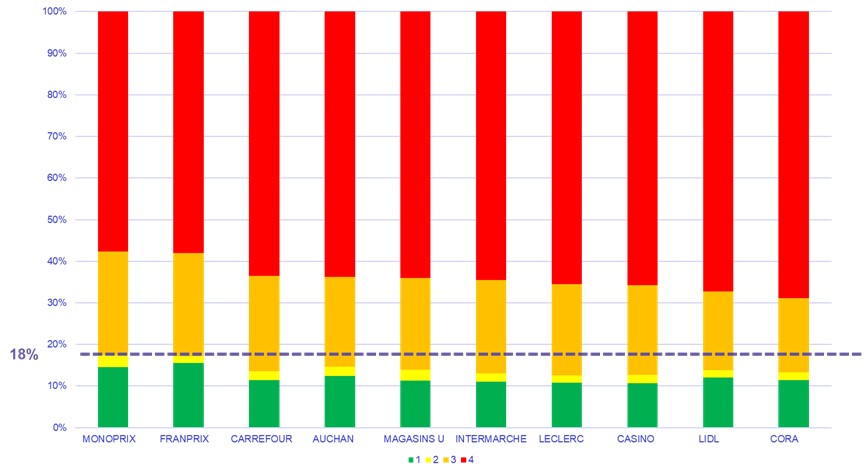
Figure 4 – Répartition des produits par classe NOVA pour les 10 enseignes les plus représentées.
Au mieux, on retrouve 18 % de produits NOVA 1 ou 2 et assez peu de différence parmi ces 10 enseignes.
Intéressons-nous maintenant aux 10 enseignes les plus vertueuses du point de vue de la classification NOVA, c’est à dire celles qui ont la part la plus importante de produits classés NOVA 1 ou 2.
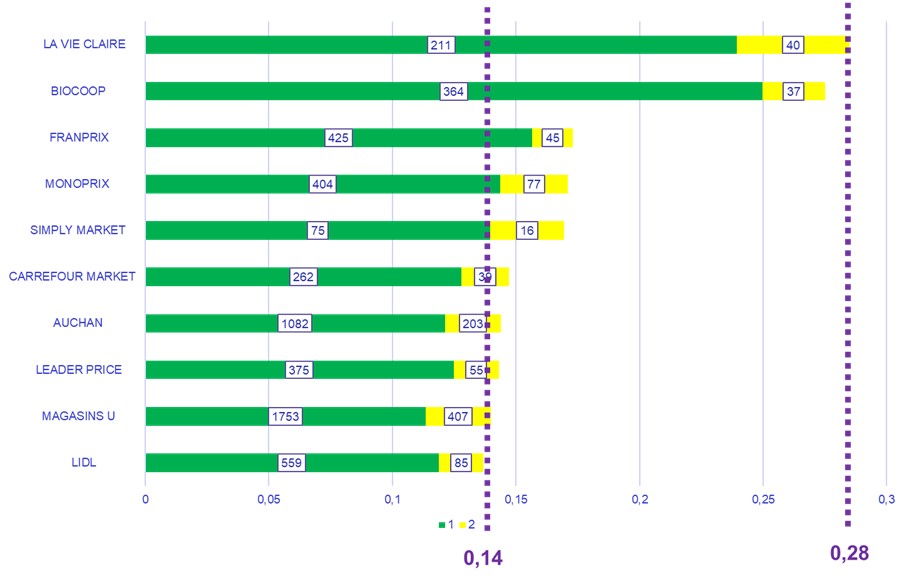
Figure 5 – Part des produits classés NOVA 1 et 2 pour les 10 enseignes les plus vertueuses.
Comme dans l’analyse sur le nutri-score, remarquons la disparité des nombres de références entre les très grandes enseignes et les autres. Nous pouvons noter ici un très net avantage pour 2 enseignes spécialisées dans le bio. Mais même pour elles, la part de classes NOVA 1 et 2 reste dans inférieure à 30 %.
A l’autre bout du spectre, les 10 enseignes ayant la part de classes NOVA 3 et 4 la plus importante sont les suivantes :
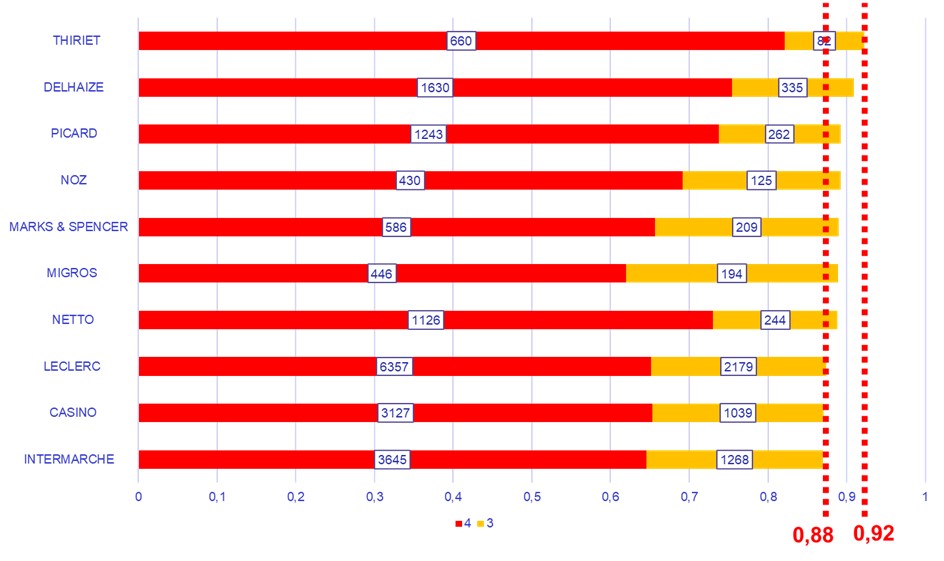
Figure 6 – Part des produits classés NOVA 3 et 4 pour les 10 enseignes les moins vertueuses
Avec près de 90 % de produits de classe NOVA 3 ou 4, les enseignes de discount ou hard discount ainsi que les enseignes de produits surgelés sont dans le bas du classement.
Conclusion
Du côté des résultats de l’étude il n’y a pas de surprise : si l’on souhaite marquer des points nutri-score et classification NOVA, il vaut mieux consommer bio, frais et non transformé, et donc aller faire ses courses dans les enseignes Biocoop ou La Vie Claire. Remarque : Picard et Thiriet sont bons au niveau des nutri-scores et mauvais sur la classification Nova. Franprix, puis Carrefour market, Auchan et Monoprix, sont dans les 10 enseignes les plus vertueuses sur les 2 critères.
Pour compléter cette étude, il faudrait également regarder l’éco-score, indicateur qui représente l’impact environnemental des produits alimentaires au cours de leurs cycle de vie (exemples de facteurs : émissions de gaz à effet de serre (CO2), destruction de la couche d’ozone, émissions de particules fines, radioactivité, toxicité, épuisement des ressources en eau…). Le risque après étude de l’impact environnemental est de ne plus pouvoir aller remplir son panier qu’au marché (circuits courts).
Du côté des outils d’analyse, outillage logiciel et matériel et méthodologie, cette mise en pratique nous a permis de dégager quelques points d’attention :
- Prévoir un temps pour la mise en place de l’environnement Hadoop et sa configuration ;
- Bien dimensionner le système, prévoir notamment l’espace nécessaire pour la réplication des données sur HDFS ;
- Prendre le temps de bien sélectionner les données initiales pour éviter de regénérer l’ensemble de l’analyse pour une caractéristique (colonne de données) négligée au départ.
Mais les avantages d’un environnement Hadoop pour traiter un grand volume de données sont nombreux :
- Rapidité d’exécution des calculs grâce à la distribution des calculs sur les différentes machines du cluster. Chaque machine se charge de réaliser les calculs sur une partie des données ;
- Sécurisation des données et calculs. Les données sont répliquées sur plusieurs machines différentes sur le cluster de sorte qu’aucune donnée ne soit perdue en cas de panne d’une ou plusieurs machines ;
- Taille évolutive du cluster. En cas d’augmentation du volume des données ou ajout de nouveaux traitements, il est aisé de rajouter de nouvelles machines sur le cluster.
Les mathématiques décisionnelles peuvent-elles contribuer à la mise en œuvre du PTEF ?
Après avoir lu le PTEF publié par le think thank The Shift Project, EURODECISION a recensé des projets d’optimisation menés par nos experts, qui ont permis d’agir sur des leviers contribuant à cette transition chez nos clients.


