En tant que société spécialisée en mathématiques décisionnelles et intelligence artificielle, EURODECISION met en place différentes technologies (optimisation, recherche opérationnelle, data science, BRMS…) pour transformer les données de nos clients en décisions optimisées. Conscients des enjeux de confidentialité, d’explicabilité et de confiance, et afin d’accompagner au mieux nos clients issus de secteurs variés (industrie, transport, défense, énergie, santé, banques et assurances…), nous tenons compte des problématiques de souveraineté dans de nombreux projets d’IA.
En particulier, l’IA générative est entrée dans les entreprises plus vite que le SI n’a pu l’encadrer, et la quasi-totalité des services grand public expose les données à des juridictions étrangères. Pourtant, en 2026, la souveraineté technique est devenue une réalité accessible : sur les cinq couches qui composent une architecture IA, quatre sont aujourd’hui pleinement maîtrisables par une entreprise européenne. Nous proposons ici un tour d’horizon pratique des choix à poser sur chacune.
Introduction
L’IA générative s’est installée dans les entreprises, ChatGPT, Claude ou Gemini sont passés du statut de curiosité à celui d’assistant quotidien. La quasi-totalité de ces services fonctionne en SaaS : chaque requête envoie les données de l’utilisateur vers les serveurs d’un fournisseur extérieur, souvent américain. Pour un usage personnel, le compromis est acceptable. Pour une entreprise qui manipule des données clients, des documents contractuels ou des secrets industriels, il n’est parfois pas envisageable.
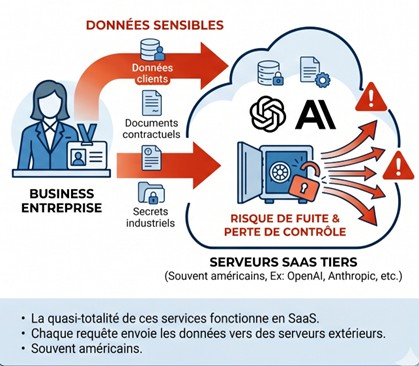
Le débat sur la souveraineté se cristallise autour de trois enjeux :
- Juridique : le RGPD encadre strictement les transferts de données personnelles hors de l’Union, et le Cloud Act américain donne aux autorités fédérales un pouvoir d’accès aux données traitées par les entreprises américaines, où que soient les serveurs.
- Stratégique : confier ses cas d’usage à un fournisseur unique, propriétaire et fermé, c’est accepter un verrouillage dont l’expérience du cloud public a montré le coût à moyen terme.
- Technique : un modèle propriétaire reste une boîte noire qu’on ne peut ni auditer, ni réentraîner sur ses propres données, ni déployer sur sa propre infrastructure.
La bonne nouvelle est que la situation a profondément changé depuis 2024. La maturation des modèles dits « open weight » — dont les poids du réseau de neurones sont publiquement distribués — et la consolidation d’un écosystème logiciel entièrement ouvert rendent désormais accessible une souveraineté technique pragmatique.
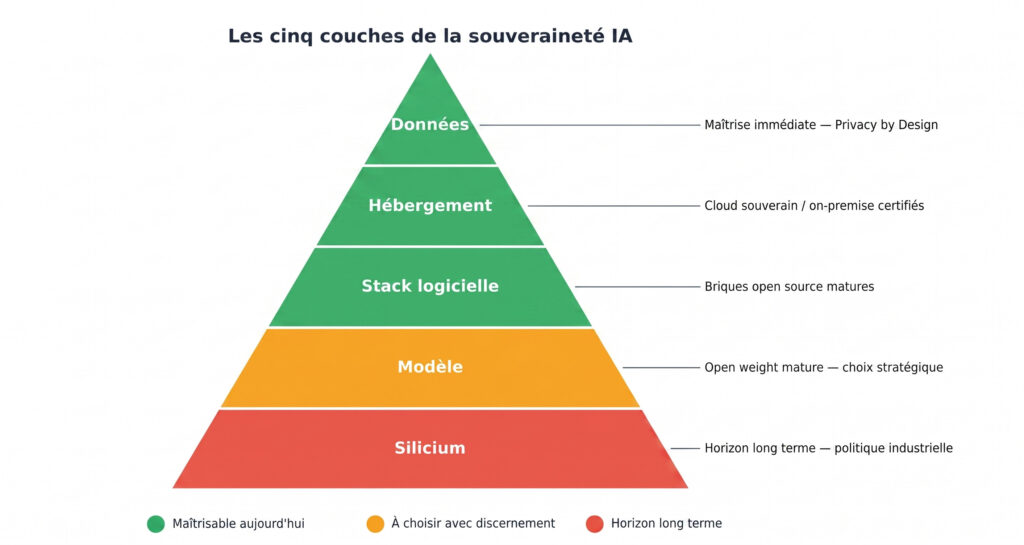
Pour s’y retrouver, il est utile de penser la souveraineté comme une architecture en couches. Cinq couches se superposent, chacune pouvant être plus ou moins maîtrisée indépendamment des autres : à la base, le silicium ; au-dessus, le modèle ; ensuite la stack logicielle ; puis l’hébergement ; et au sommet, les données. Quatre d’entre elles sont aujourd’hui pleinement maîtrisables ; seul le silicium reste un horizon de long terme.
Un marché mondial à trois vitesses
Le marché des grands modèles s’est structuré en 2026 autour de trois blocs aux trajectoires très différentes.
Les États-Unis gardent leur leadership avec des acteurs propriétaires fermés (Anthropic, OpenAI, Google DeepMind) dont les modèles tiennent le haut des classements. À côté de cette offre fermée, Meta poursuit la série Llama et Google publie Gemma 4 sous Apache 2.0 (licence open source) depuis avril 2026. Les contreparties à l’usage des modèles propriétaires américains restent connues : exposition au Cloud Act, fine-tuning impossible, tarification subie et surtout l’envoi des données.
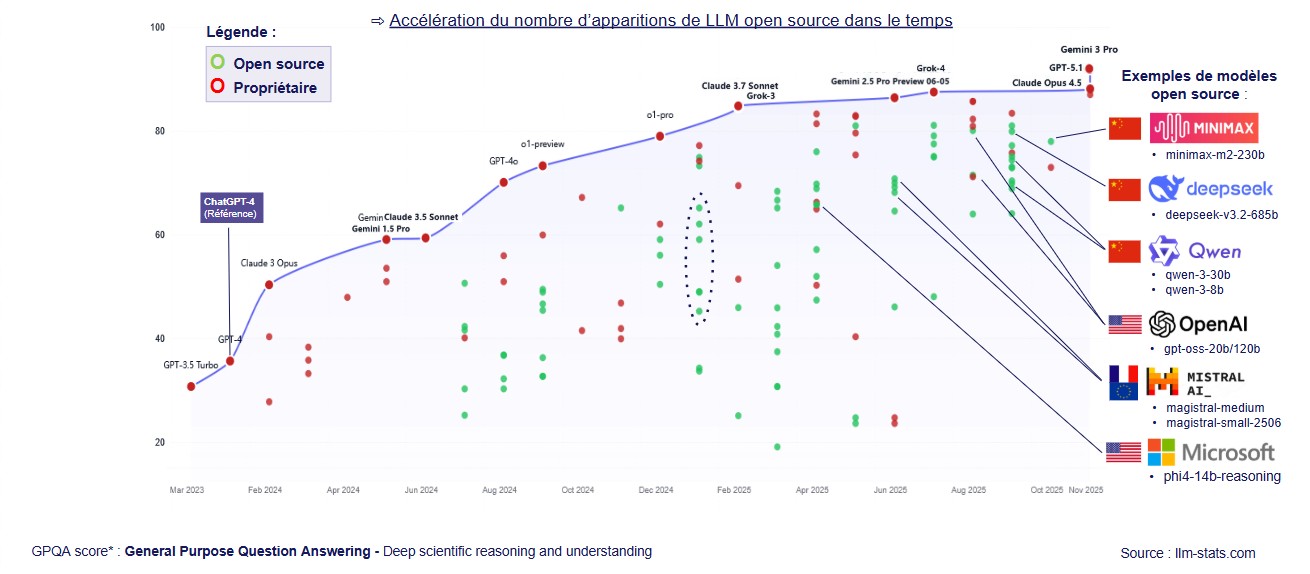
La Chine a constitué la surprise stratégique du domaine. DeepSeek, Alibaba (Qwen), Moonshot AI (Kimi), Z.ai (GLM), Tencent (Hunyuan) : la profondeur du catalogue est désormais comparable à celle des États-Unis, et l’écart de performances s’est réduit (2,7 points sur le classement Arena en mars 2026, contre 17 à 31 points en mai 2023). Particularité importante : l’essentiel des modèles chinois est publié sous licence permissive, ce qui en fait des candidats sérieux pour les déploiements souverains européens.
L’Europe accuse un retard quantitatif. Selon le Stanford AI Index 2026, 50 modèles d’IA notables ont été produits aux États-Unis en 2025, 30 en Chine, et seulement 3 en Europe. Mistral AI, basé à Paris, concentre l’essentiel de l’offre — nous y revenons en détail dans la section consacrée à la couche modèle. Le paradoxe européen reste entier : le continent consomme massivement de l’IA générative mais en produit peu en propre.
Cette asymétrie de production ne doit toutefois pas dicter les choix d’architecture. Il n’est pas nécessaire de produire ses propres modèles frontières pour construire une IA souveraine : il suffit de bien choisir parmi ce que l’écosystème ouvert met à disposition. Encore faut-il commencer par regarder la couche la plus basse et la plus contrainte de la pyramide : le silicium.
La couche silicium : la contrainte
Tout modèle a besoin de hardware. Et la couche silicium est de très loin la plus concentrée et la moins maîtrisable des cinq pour une entreprise européenne.
NVIDIA y conserve une position de quasi-monopole, avec environ 80 % du marché des accélérateurs d’IA. Le vrai verrou n’est pas le matériel : c’est CUDA, l’écosystème logiciel propriétaire que NVIDIA construit depuis près de vingt ans. Tous les frameworks d’apprentissage profond et l’essentiel des outils de fine-tuning supposent CUDA comme socle.
Les challengers américains existent — AMD, TPU de Google, Trainium d’AWS, puces internes Microsoft et Meta — mais restent dans la sphère américaine. Côté chinois, les sanctions américaines de 2022 ont eu un effet contre-productif. Coupée des GPU NVIDIA haut de gamme, l’industrie chinoise a investi massivement dans son silicium domestique. Huawei produit ses propres puces, la dynamique est lancée, même si la capacité reste loin de celle de NVIDIA.
L’Europe accuse sur cette couche trois décennies de retard. Pas de fondeur avancé sur le continent, dépendance totale à TSMC. Un signal émerge néanmoins : la société française SiPearl, qui équipe les supercalculateurs européens JUPITER. Le positionnement est volontairement modeste — inférence, pas entraînement — mais c’est la première proposition crédible d’une pile matérielle européenne.
Pour une entreprise, le constat est sans appel : la souveraineté complète sur le silicium n’est pas réaliste à court ou moyen terme. Ce n’est pas pour autant un blocage. Les quatre couches du dessus peuvent être maîtrisées indépendamment, et c’est sur elles que se joue l’essentiel.
Le signal NVIDIA DGX Spark
Une initiative récente de NVIDIA illustre que le fournisseur dominant a compris l’évolution de la demande. Disponible depuis octobre 2025, le DGX Spark est un « supercalculateur IA personnel » au format desktop. La machine, compacte et silencieuse, embarque 128 Go de mémoire unifiée. Elle permet de faire tourner localement des modèles jusqu’à 200 milliards de paramètres et d’en fine-tuner jusqu’à 70 milliards. Le tarif d’entrée, autour de 4 800 euros en Europe, la positionne très en dessous des serveurs GPU traditionnels.
Pour une équipe de R&D, une cellule data science, un cabinet d’avocats ou un centre de soins qui veut disposer d’un assistant sur des données sensibles sans rien envoyer à l’extérieur, le calcul devient évident face à la location de GPU dans le cloud.
Plus important encore que la machine, c’est le signal stratégique qu’elle représente. NVIDIA, leader incontesté, lance un produit dont l’argument principal est la maîtrise locale et la souveraineté des données. Le fait que le fournisseur dominant identifie cette demande montre que le rapatriement de l’IA sur site n’est pas un caprice européen, mais une tendance de fond. Le DGX Spark reste du NVIDIA — donc du CUDA, donc une dépendance américaine — mais il permet à une organisation de récupérer instantanément la maîtrise des quatre couches du dessus. C’est précisément celles-ci que nous parcourons maintenant, en commençant par le modèle.
La couche modèle : l’open weight
La distinction clé pour s’orienter est celle entre open source et open weight. L’open source au sens strict suppose que les données d’entraînement, le code et les poids soient tous publiés. En pratique, dans l’immense majorité des cas, seuls les poids sont diffusés : c’est de l’open weight. La nuance conditionne ce qu’on peut faire du modèle (le déployer, le fine-tuner) et ce qu’on ne peut pas faire (le reproduire à l’identique). Pour la plupart des cas d’usages industriels, l’open weight est suffisant.
La cartographie 2026 reproduit la géopolitique des modèles propriétaires en l’amplifiant. Côté américain, Meta poursuit Llama, Google publie Gemma 4 sous Apache 2.0 et Microsoft maintient la famille Phi sous licence MIT. Côté chinois, le rythme est devenu effréné : DeepSeek a lancé V4 en mai 2026, Alibaba a publié la série Qwen 3.6 dans la foulée, et Z.ai, Moonshot et Tencent suivent.
L’offre européenne : Mistral et LightOn
Côté européen, Mistral AI publie ses modèles de petite et moyenne taille sous licence Apache 2.0, avec une gamme couvrant Large 3 (généraliste), Medium 3.5 (orienté agents et code), Small 4 (architecture MoE), Devstral (code) et Magistral (raisonnement). Plutôt que de courir derrière les modèles géants, l’entreprise mise sur des modèles plus petits et plus spécialisés, optimisés pour le déploiement en entreprise. C’est une approche pragmatique qui correspond bien aux besoins industriels : la plupart des cas d’usage métier — extraction d’informations, classification, génération assistée, RAG — ne réclament pas un modèle de raisonnement de niveau doctoral, mais un modèle rapide, fine-tunable et déployable sur infrastructure maîtrisée.
À côté de Mistral, LightOn mérite d’être mentionné. Cette société parisienne, fondée en 2016, est devenue en novembre 2024 la première startup européenne d’IA générative cotée en bourse. Sa plateforme Paradigm fournit une couche d’orchestration et de RAG d’entreprise, déployable on-premise ou en cloud souverain, qui s’appuie sur des modèles open weight. LightOn illustre un positionnement intéressant : ne pas concurrencer les producteurs de modèles, mais fournir la couche logicielle souveraine qui permet aux grandes entreprises et aux acteurs publics de déployer concrètement l’IA générative dans un cadre juridique européen.
État des lieux : performances comparées
Le tableau ci-dessous synthétise les principaux modèles disponibles en mai 2026. Les deux premières lignes correspondent aux modèles propriétaires de référence ; les lignes suivantes regroupent les modèles open weight. GPQA Diamond mesure la capacité à répondre à des questions de niveau doctoral en sciences ; c’est un indicateur de raisonnement profond. SWE-bench Verified mesure la capacité à résoudre des bugs réels dans des projets open source ; c’est un indicateur pour les usages de code.
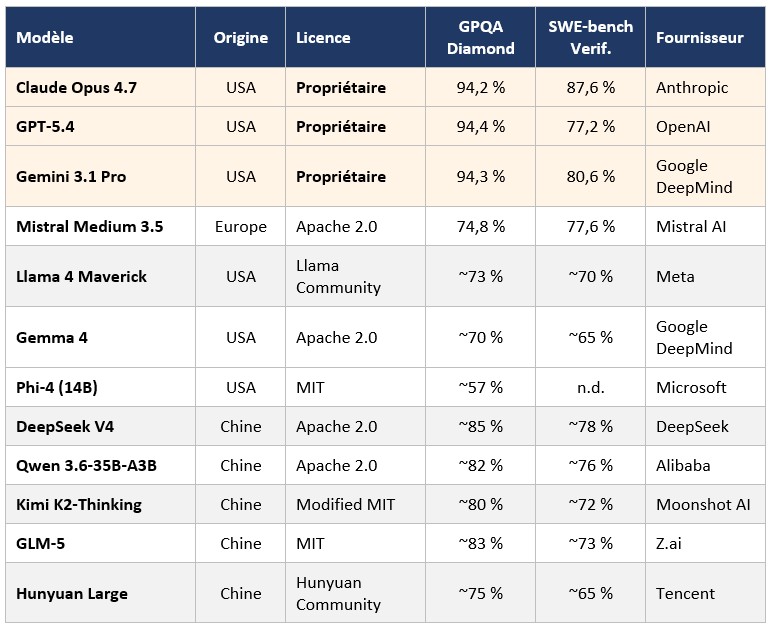
Sur GPQA Diamond, le sommet du domaine est saturé : Claude Opus 4.7, GPT-5.4 et Gemini 3.1 Pro sont indiscernables autour de 94 %. Les meilleurs modèles open weight chinois se situent entre 80 et 85 %, soit une dizaine de points d’écart. Sur SWE-bench Verified, l’écart est encore plus réduit, et Mistral Medium 3.5 atteint 77,6 % — un niveau largement suffisant pour la majorité des cas d’usage applicatifs.
La domination chinoise sur l’open weight est aujourd’hui quantitative et qualitative. Mistral reste le seul acteur européen capable de produire des modèles ouverts de niveau international, avec un écart mesurable sur le raisonnement profond mais un positionnement plus compétitif sur les usages applicatifs.
Leanstral, un exemple de spécialisation
L’illustration la plus parlante de la stratégie Mistral est Leanstral, publié en mars 2026 sous Apache 2.0. C’est un modèle spécialisé dans la rédaction et la vérification de preuves formelles en Lean 4, l’assistant de preuve utilisé en mathématiques et en vérification de programmes. Les résultats obtenus avec ce petit modèle open source spécialisé sont très parlants :
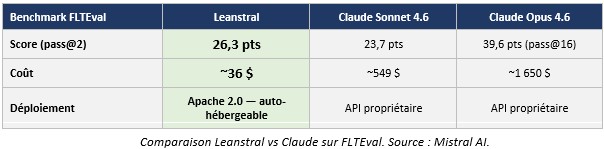
Sur une tâche bien définie, un petit modèle ouvert spécialisé peut donc rivaliser avec — voire battre — les modèles propriétaires les plus puissants, à une fraction du coût et avec la maîtrise complète de l’infrastructure. C’est précisément le pattern qui correspond aux besoins industriels.
Les licences open weight
Un modèle open weight ne signifie pas un modèle utilisable sans contrainte. Les licences varient et leur lecture juridique est un préalable à tout déploiement.
Les licences Apache 2.0 et MIT, qui régissent par exemple Mistral, DeepSeek, Gemma 4 et GLM-5, sont permissives au point de ne pas nécessiter de revue juridique préalable. Elles autorisent l’usage commercial, la modification, la redistribution. C’est le choix le plus simple pour un déploiement industriel.
La Llama Community License de Meta introduit une clause spécifique : au-delà de 700 millions d’utilisateurs actifs mensuels, une licence séparée doit être négociée. Cette clause vise les concurrents directs et n’a quasiment aucune incidence sur une entreprise européenne, mais elle exclut le modèle des qualifications de logiciel libre au sens strict.
La Mistral Research License, applicable aux modèles plus ambitieux de Mistral non distribués sous Apache, restreint l’usage à la recherche non commerciale. Les entreprises doivent identifier précisément quelle gamme de modèles elles peuvent utiliser librement.
Le fine-tuning, l’argument souvent oublié
Au-delà de la souveraineté juridique, il existe un argument technique fort en faveur de l’open weight : la possibilité de réentraîner le modèle sur ses propres données. Avec un modèle propriétaire fermé, l’opération est impossible. Avec un modèle open weight, elle est désormais standard et abordable, grâce à des techniques comme LoRA qui permettent de fine-tuner un modèle de plusieurs dizaines de milliards de paramètres sur du matériel modeste.
L’intérêt pratique est considérable. Un assistant véritablement spécialisé sur la rédaction de comptes-rendus médicaux, sur la classification de tickets de support, sur la génération de code dans un langage interne : autant de cas d’usage où le fine-tuning transforme un modèle générique en outil expert. Pour beaucoup d’entreprises, les motifs réels du choix de l’open weight sont autant la souveraineté juridique que la capacité à spécialiser le modèle.
Une fois le modèle choisi, encore faut-il l’orchestrer, lui adjoindre une mémoire documentaire et une interface utilisable. C’est l’objet de la couche suivante : la stack logicielle.
La couche stack logicielle : assembler un assistant complet en open source
Un modèle, même open weight, ne suffit pas. Pour en faire un assistant utilisable, il faut une chaîne d’outils complète : interface, récupération de contexte, base vectorielle, orchestration, serveur d’inférence. Suivons le parcours d’une requête, de l’utilisateur au modèle et retour, pour voir comment chaque brique se met en place — et constater qu’elles existent toutes en open source, à un niveau de maturité industriel.
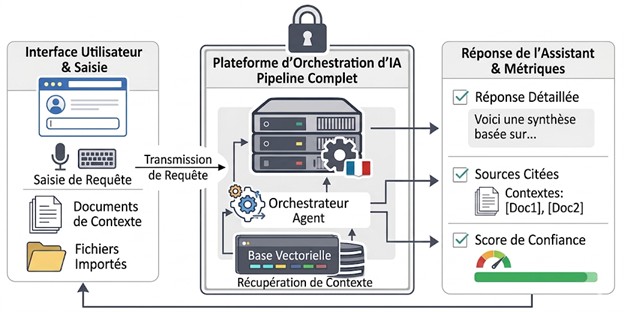
L’interface utilisateur est le point d’entrée. Des projets comme OpenWebUI ou LibreChat fournissent une expérience proche de ChatGPT, entièrement auto-hébergeable, avec gestion des utilisateurs, historique des conversations et support multi-modèles. Pour l’utilisateur final, l’expérience est indistinguable d’un service propriétaire. Pour le responsable du SI, tout reste sous contrôle : pas d’envoi de données vers l’extérieur, stockage des conversations et préférences utilisateurs en local, intégration SSO native dans le SI de l’entreprise.
Derrière l’interface, un framework d’orchestration — LangChain, LlamaIndex ou Haystack — joue le rôle de squelette : il enchaîne les appels au modèle, gère la mémoire conversationnelle et coordonne les éventuels outils externes. Lorsqu’une requête utilisateur arrive, c’est lui qui décide quelles informations injecter dans le prompt.
C’est là qu’intervient le RAG (Retrieval-Augmented Generation), devenu le pattern dominant pour faire répondre un LLM sur des données spécifiques à l’entreprise. Les documents internes sont stockés dans une base vectorielle — Qdrant, Weaviate, Chroma etc — qui recherche, pour chaque requête utilisateur, les extraits de documents les plus pertinents, afin d’enrichir le contexte du LLM. Mais ce mécanisme repose sur un composant souvent négligé : les embeddings, c’est-à-dire les modèles qui traduisent un texte en vecteur mathématique. D’excellents embeddings open weight existent (BGE, E5, Mistral, Qwen) et peuvent tous être déployés en local. Utiliser un service d’embeddings américain ou sur un serveur externe pour vectoriser une base documentaire interne revient à envoyer l’intégralité de cette base vers le fournisseur — la maîtrise juridique du reste de la pile serait annulée par cette seule porte de sortie.
Une fois le contexte rassemblé, le tout part vers le serveur d’inférence qui fait tourner concrètement le modèle pour générer du texte. Des moteurs spécialisés comme vLLM ou Ollama permettent d’exécuter un modèle de plusieurs dizaines de milliards de paramètres sur des serveurs GPU classiques, où l’exécution reste locale (traitement des données d’entrées et réponse du LLM sans envoi de données vers l’extérieur).
Pour les usages plus avancés, une couche agentique vient se greffer dessus : c’est la capacité du LLM à orchestrer des outils et à enchaîner des actions de manière autonome. Le protocole MCP (Model Context Protocol), proposé par Anthropic en 2024, standardise désormais la façon dont un agent peut découvrir et appeler des outils.
Toute la chaîne d’un assistant comparable à ChatGPT peut donc être reconstruite avec des briques entièrement ouvertes, sans aucune dépendance à un fournisseur propriétaire. C’est un changement profond par rapport à 2023, où chaque composant nécessitait encore un service externe. Reste à décider où cette chaîne va concrètement tourner.
La couche hébergement : où tourne vraiment le modèle
Un modèle open weight hébergé chez AWS, Azure ou GCP reste, en raison du Cloud Act, dans une dépendance juridique américaine, indépendamment du fait que les serveurs physiques soient à Francfort ou à Dublin. La nationalité du fournisseur prime sur la localisation des machines.
Trois options s’offrent en pratique aux entreprises, avec des compromis différents.
L’on-premise souverain consiste à exploiter ses propres serveurs, dans ses propres locaux ou dans un data center loué en bare metal. C’est le niveau de maîtrise maximal : les données ne sortent jamais du SI de l’entreprise, et aucune juridiction étrangère ne peut intervenir. La contrepartie est un coût initial significatif et une expertise opérationnelle à constituer.
Le cloud privé ou cloud de confiance consiste à louer une infrastructure dédiée chez un prestataire soumis exclusivement au droit européen. C’est le compromis le plus courant : flexibilité du cloud, sans exposition aux lois extraterritoriales. Les acteurs français de référence sont OVHcloud, Scaleway, Outscale, NumSpot.
L’API cloud public offre le déploiement le plus rapide mais expose les données aux risques décrits plus haut. Pour des cas d’usage non sensibles, cela peut rester acceptable. Pour des données métier ou réglementées, c’est rarement le bon choix.
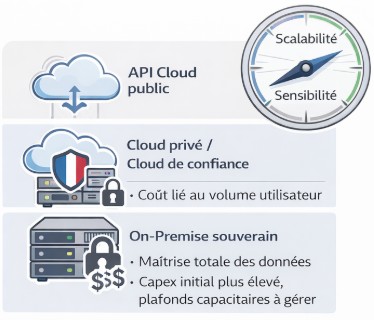
Il n’existe pas de bonne réponse unique : un POC peut démarrer sur API publique pour tester rapidement, migrer vers du cloud privé en MVP, puis vers de l’on-premise quand le système devient un enjeu stratégique. L’important est que la décision soit éclairée.
La couche données : la fuite invisible
L’hébergement souverain n’est pas suffisant. Encore faut-il que la donnée elle-même reste dans l’enceinte maîtrisée tout au long de son cycle de vie. Plusieurs scénarios courants laissent fuir la donnée alors même que l’infrastructure semble bien protégée.
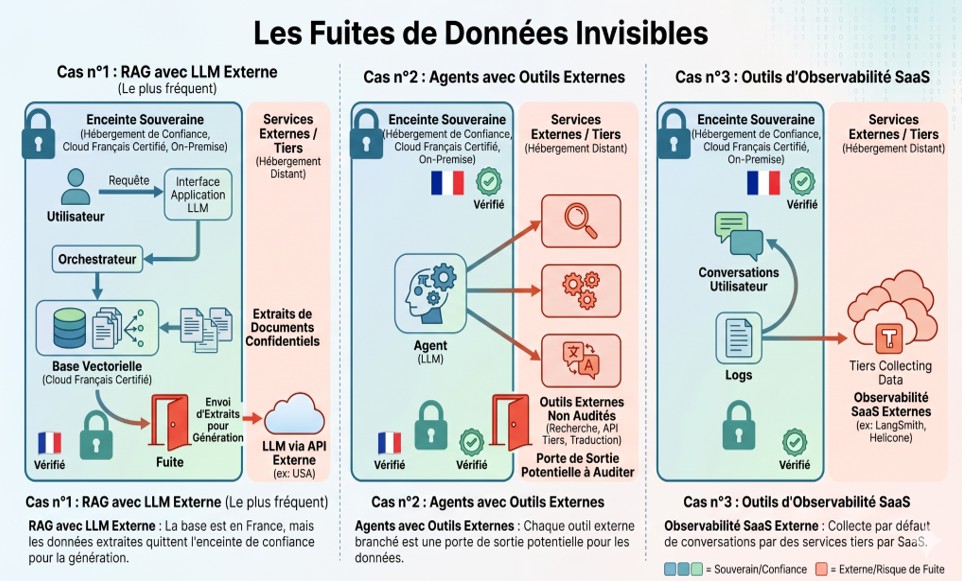
Le cas du RAG est le plus fréquent. Une entreprise a soigneusement hébergé sa base vectorielle sur un cloud français certifié, et a indexé tous ses documents internes. Mais si le LLM appelé pour générer les réponses est une API externe, alors à chaque requête, les extraits de documents (parfois confidentiels) extraits de la base sont envoyés vers les serveurs externes du fournisseur. La base de données reste en France, les documents extraits, non. La fuite est invisible mais bien réelle.
Le cas des agents introduit une difficulté supplémentaire. Un agent — un LLM capable d’appeler des outils externes (recherche web, API tierces, traduction) — sort de l’enceinte souveraine à chaque appel externe. Chaque outil branché est une porte de sortie potentielle à auditer.
La politique de réentraînement est une autre zone grise. Quand on consomme un service d’IA externe, la première question est : que devient notre donnée après le traitement ? Les conditions d’usage proposent souvent des options pour exclure le réentraînement, mais c’est une garantie contractuelle, pas technique. Une garantie technique vérifiable, par audit ou par déploiement on-premise, est toujours préférable.
Les outils d’observabilité méritent une mention particulière. Pour monitorer une application LLM en production, on utilise typiquement des plateformes comme LangSmith ou Helicone. Ce sont des services SaaS américains, qui collectent par défaut une partie significative des conversations. Dans un contexte souverain, ils doivent être remplacés par des équivalents auto-hébergés comme LangFuse.
Plusieurs bonnes pratiques permettent de minimiser les fuites. Le Privacy by Design consiste à anonymiser ou pseudonymiser les données sensibles en amont, avant qu’elles n’atteignent le modèle. La traçabilité complète, exigée par la CNIL et par l’AI Act pour les systèmes à haut risque, suppose que chaque appel et chaque transformation soient journalisés. La non-réutilisation des données pour le réentraînement doit être contractuellement garantie et techniquement vérifiable. Enfin, l’auditabilité bout-en-bout est désormais une exigence courante dans les appels d’offres sensibles.
Le cadre réglementaire : RGPD, AI Act et certifications sectorielles
Le cadre juridique européen entoure désormais l’IA générative de manière dense, et c’est plutôt une bonne nouvelle pour les entreprises qui ont fait le choix d’une architecture souveraine.
Le RGPD reste le socle structurant principal. Toute donnée à caractère personnel traitée par une IA générative tombe sous son périmètre : un assistant qui traite des dossiers clients, un outil qui s’appuie sur des courriels internes, un RAG qui indexe des documents RH. Les principes connus s’appliquent : base légale, finalité, minimisation, durée de conservation, droits des personnes.
L’IA générative pose plusieurs questions spécifiques. La base légale du traitement des données d’entraînement reste un débat ouvert. Les prompts utilisateurs peuvent contenir des données personnelles non anticipées. Les logs de conversation doivent être conservés pour des raisons opérationnelles, mais leur durée est contrainte. Et la question du droit à la rectification, dans un système qui peut « halluciner » des informations sur une personne réelle, reste largement ouverte sur le plan jurisprudentiel.
L’AI Act, en cours d’application progressive, complète ce cadre par une approche fondée sur le niveau de risque. Certaines pratiques sont interdites. Les systèmes classés à haut risque (recrutement, scoring crédit, applications médicales, justice) sont soumis à des obligations renforcées de documentation et de supervision humaine. Les contenus générés par IA doivent être identifiés comme tels. Le calendrier précis est susceptible d’évoluer, mais la direction est claire : plus le système est sensible, plus la traçabilité exigée est forte.
À côté de ces textes, des réglementations sectorielles s’ajoutent : HDS pour la santé, DORA pour les acteurs financiers, NIS2 pour les opérateurs de services essentiels, et des référentiels spécifiques pour la défense ou l’énergie.
Ces exigences sont, par construction, plus faciles à satisfaire avec une architecture souveraine maîtrisée. La traçabilité bout-en-bout, la localisation des données, la non-réutilisation, la supervision humaine : tous ces points trouvent leur réponse naturelle dans une pile entièrement maîtrisée, là où ils deviennent des sources de tension permanentes avec une dépendance à un fournisseur propriétaire externe. Une entreprise qui investit aujourd’hui dans la souveraineté de son IA générative ne fait pas que protéger ses données : elle prépare son alignement réglementaire à coût marginal.
Synthèse
La souveraineté technologique en IA générative n’est pas une question binaire mais une architecture stratifiée. Cinq couches doivent être considérées, et chacune peut être maîtrisée indépendamment des autres : les données par des pratiques d’anonymisation et de traçabilité ; l’hébergement par des offres souveraines européennes désormais matures et certifiées ; la stack logicielle par des briques open source de qualité industrielle ; et le modèle, grâce à l’accélération de l’open weight, par des alternatives crédibles pour la grande majorité des cas d’usage.
Le silicium reste un horizon de long terme. Cette dépendance ne peut pas être effacée en deux ou trois ans, mais elle ne doit pas non plus paralyser l’action. Le fait que NVIDIA elle-même propose désormais des solutions explicitement conçues pour le calcul local — à l’image du DGX Spark — montre que la demande de souveraineté est reconnue jusqu’au sommet.
DecideOm et EURODECISION participeront au salon Souveraineté Numérique